难道我发现了进阶版思维链?
在日常测试大模型过程中,我发现一个有趣的事情,一道看似简单的题: “一只小船能载 2 人,一共有 7 人要过河,问要来回几次才能把所有人都送到对岸?”,居然通用模型即便使用 CoT 提示 “Think Step by Step” 都无法答对,包括 GPT-4o, GPT-4.5, Claude 3.5 sonnet 也无法答对。Claude 3 Opus, Gemini 2.0 Flash, Gemini 2.0 全部失败。
而 DeepSeek V3 和 Grok3 (不开 Think)以及所有推理模型比如 o1 等等都能答对。
但是,如果我对通用模型修改一下 CoT 提示 “ Think step by step and write the detail analysis” ,GPT-4.5, Claude 3.5 sonnet,就能回答对了。
诡异的是,GPT-4o 依然错误!
完全出乎我的意料,要知道,现在别说 GPT-4.5 了,就是 GPT-4o,对于一些以前用来测试模型的推理题比如寻找大家共同的开会时间、甚至更难点的,不用 CoT 提示基本都能答对了,而这个看来如此简单的题,为什么会成了障碍呢?
于是我索性对手边各类模型来了个“统一测试”,总结了完整对比表格和结论。这篇文章就跟大家聊聊其中的奥妙。
如果你想直接阅读英文原文,可以从这里开始往下看,也欢迎点击我在 Zenodo 上的链接下载 PDF:10.5281/zenodo.15092746
Prompt Specificity in River-Crossing Logic: A Comparative Study of General-Purpose vs. Reasoning-Optimized LLMs
Abstract
This paper investigates how different prompting strategies affect large language models (LLMs) when solving a seemingly straightforward puzzle: transporting 7 people across a river in a 2-person boat. We compare "general-purpose" models (GPT-4o, GPT-4.5, Claude 3.5 Sonnet, Gemini 2.0 Flash, DeepSeek V3, Grok 3) and "reasoning-optimized" models (GPT o1, GPT o3-mini-high, Claude 3.7 Sonnet Extended Thinking, Gemini 2.5 Pro, Gemini 2.0 Flash Thinking, DeepSeek R1, Grok 3 Thinking) under three prompt conditions:
- No Chain-of-Thought (CoT),
- A simple CoT hint ("Think step by step"),
- A more detailed CoT prompt ("Think step by step and write the detail analysis").
We observe that some general-purpose models fail unless given a very explicit prompt—sometimes contradicting expectations of their advanced reasoning abilities—whereas others (including newly updated "general" versions) succeed even without CoT. Notably, GPT-4o, an ostensibly reliable GPT-4 variant, consistently fails under all prompt types. Meanwhile, all tested reasoning-optimized models solve the puzzle correctly in every scenario. We discuss how these findings reveal surprising vulnerabilities in older or baseline models, question whether prompt hints merely trigger existing logic modules, and highlight how "general vs. reasoning" boundaries are increasingly blurred.
1. Introduction
Large Language Models (LLMs) have demonstrated remarkable capabilities in tasks requiring knowledge retrieval, text generation, and limited forms of logical reasoning. However, small yet precise logic puzzles—like the classic "boat can carry two, 7 people crossing" problem—can expose unexpected weaknesses. One particularly striking example is the consistent failure of GPT-4o, despite GPT-4 being widely considered "relatively reliable" in logical tasks. This highlights the reality that some older or baseline LLM versions still struggle with seemingly trivial puzzles, even though more advanced or newly fine-tuned models handle them with ease.
To explore why such failures occur, we investigate:
- How do standard vs. detailed Chain-of-Thought (CoT) prompts affect puzzle-solving accuracy in LLMs?
- Why do certain older variants (e.g., GPT-4o) fail systematically, while many reasoning-optimized or newly updated "general" models succeed?
- Does "Think step by step" truly switch on an internal logic module, or is it insufficient for some LLMs without an even more elaborate directive?
By comparing both “general-purpose" and “reasoning-optimized" models under three prompt conditions (no CoT, simple CoT, and detailed CoT), we shed light on the interplay of prompt specificity and model architecture. In doing so, we illustrate a potentially “shocking" fact: some older or established models can repeatedly fail a basic puzzle—a cautionary reminder that vendor or version labels do not guarantee robust reasoning for every scenario.
2. Related Work
Chain-of-Thought prompting (CoT) has been shown to improve multi-step reasoning by prompting the model to "show its work" [1,2]. Meanwhile, commercial LLM deployments often introduce specialized "reasoning" or "extended thinking" variants, further complicating the landscape [3,4]. Although prior research highlights that the same model can perform significantly better or worse under slightly different prompts [1,2], less attention has been paid to consistently failing older or baseline versions that do not respond well to any form of CoT.
Our study contributes by:
- Demonstrating that certain well-known older variants (GPT-4o) can exhibit surprising failures,
- Systematically comparing "general" vs. "reasoning" solutions on a single puzzle with minimal vs. detailed CoT,
- Discussing how the puzzle’s language ambiguity (“来回几次?") influences numeric answers, further stressing the importance of clear puzzle definitions.
3. Methodology
3.1 Puzzle Description
We use the puzzle:
“A boat can carry exactly 2 people at a time. There are 7 people who need to cross a river. How many trips back and forth does it take to get everyone across?"
Key constraints:
- The boat cannot move by itself; at least 1 person must row.
- A minimal solution typically yields 11 single crossings (or 5 complete round trips + 1 final one-way).
- The Chinese phrasing "来回几次" can cause confusion, producing answers from 5 to 13.
3.2 Prompt Types
Each model was tested under three prompt conditions:
- No CoT — No special instructions, just the puzzle question.
- Simple CoT — Appended "Think step by step."
- Detailed CoT — Appended "Think step by step and write the detail analysis."
3.3 Models: General vs. Reasoning
We group models into:
- General-Purpose: GPT-4o, GPT-4.5, Claude 3.5 Sonnet, Gemini 2.0 Flash, DeepSeek V3, Grok 3
- Reasoning-Optimized: GPT o1, GPT o3-mini-high, Claude 3.7 Sonnet Extended Thinking, Gemini 2.5 Pro, Gemini 2.0 Flash Thinking, DeepSeek R1, Grok 3 Thinking
Notable Surprise: GPT-4o, historically aligned with GPT-4’s robust reputation, performed poorly here. Meanwhile, some "general" versions (DeepSeek V3) show strong built-in logic, emphasizing that these category labels are no longer reliable proxies for actual performance.
3.4 Data Collection
- Test Setup: Each model was queried in an isolated session, avoiding prior context contamination.
- Evaluation: We labeled an answer "Correct" if it either yields the minimal crossing count (11 single trips) or clearly explains the 5–6 round-trip logic.
- Repeated Trials: If a model gave inconsistent answers across attempts, we recorded the first stable or majority result.
4. Results
Table 1 summarizes correctness under no CoT, simple CoT, and detailed CoT prompts.
Table 1. Performance Across Prompts
| Model | Type | No CoT | Simple CoT | Detailed CoT | Comment |
|---|---|---|---|---|---|
| GPT-4o | General | Fail | Fail | Fail | Unexpectedly fails in all conditions—see Sec. 5.1 |
| GPT-4.5 | General | Fail | Fail | Correct | Needs highly explicit "detailed analysis" |
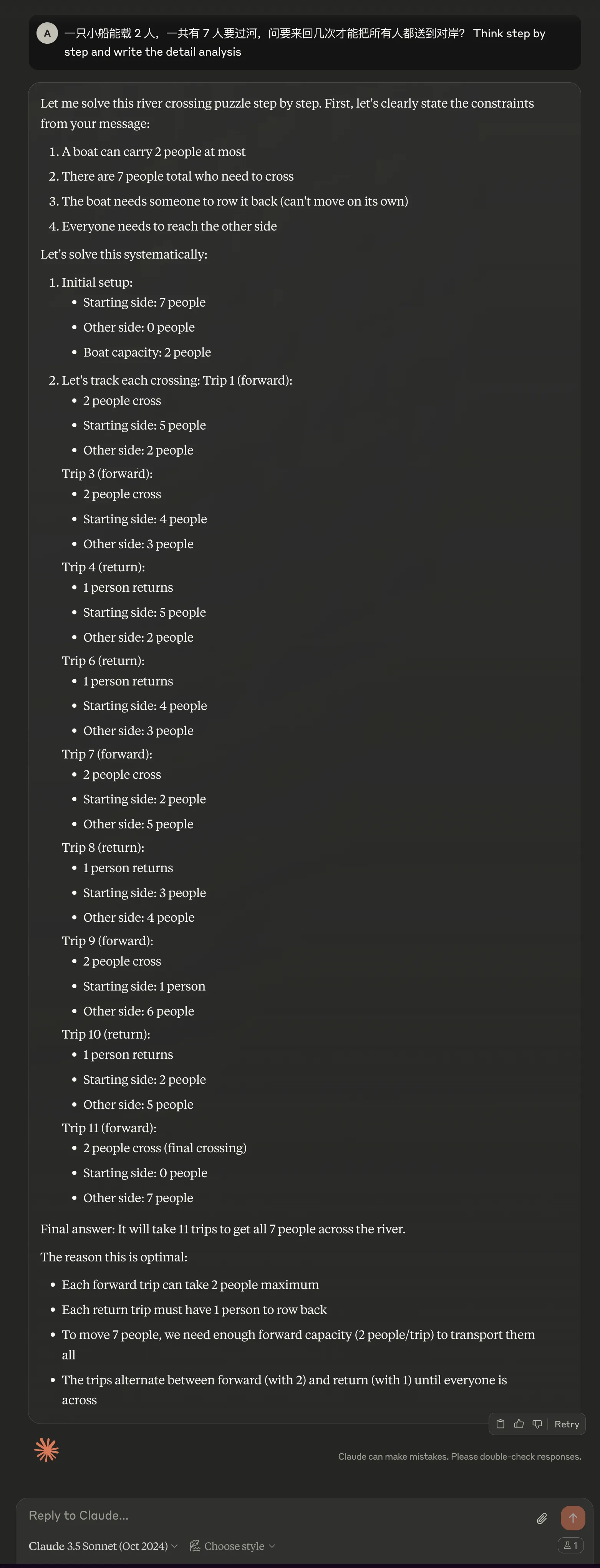
| Claude 3.5 Sonnet | General | Fail | Fail | Correct | Similar pattern to GPT-4.5 |
| Gemini 2.0 Flash | General | Fail | Fail | Fail | All tested prompts yield incorrect answers |
| DeepSeek V3 | General | Correct | Correct | Correct | Built-in stepwise logic, no special CoT needed |
| Grok 3 | General | Correct | Correct | Correct | Also robust without explicit CoT |
| GPT o1 | Reasoning | Correct | Not tested | Not tested | Provided direct formula (2n−3 = 11) |
| GPT o3-mini-high | Reasoning | Correct | Not tested | Not tested | Also used the minimal crossing formula |
| Claude 3.7 Ext Thinking | Reasoning | Correct | Not tested | Not tested | Detailed logic chain yields 11 |
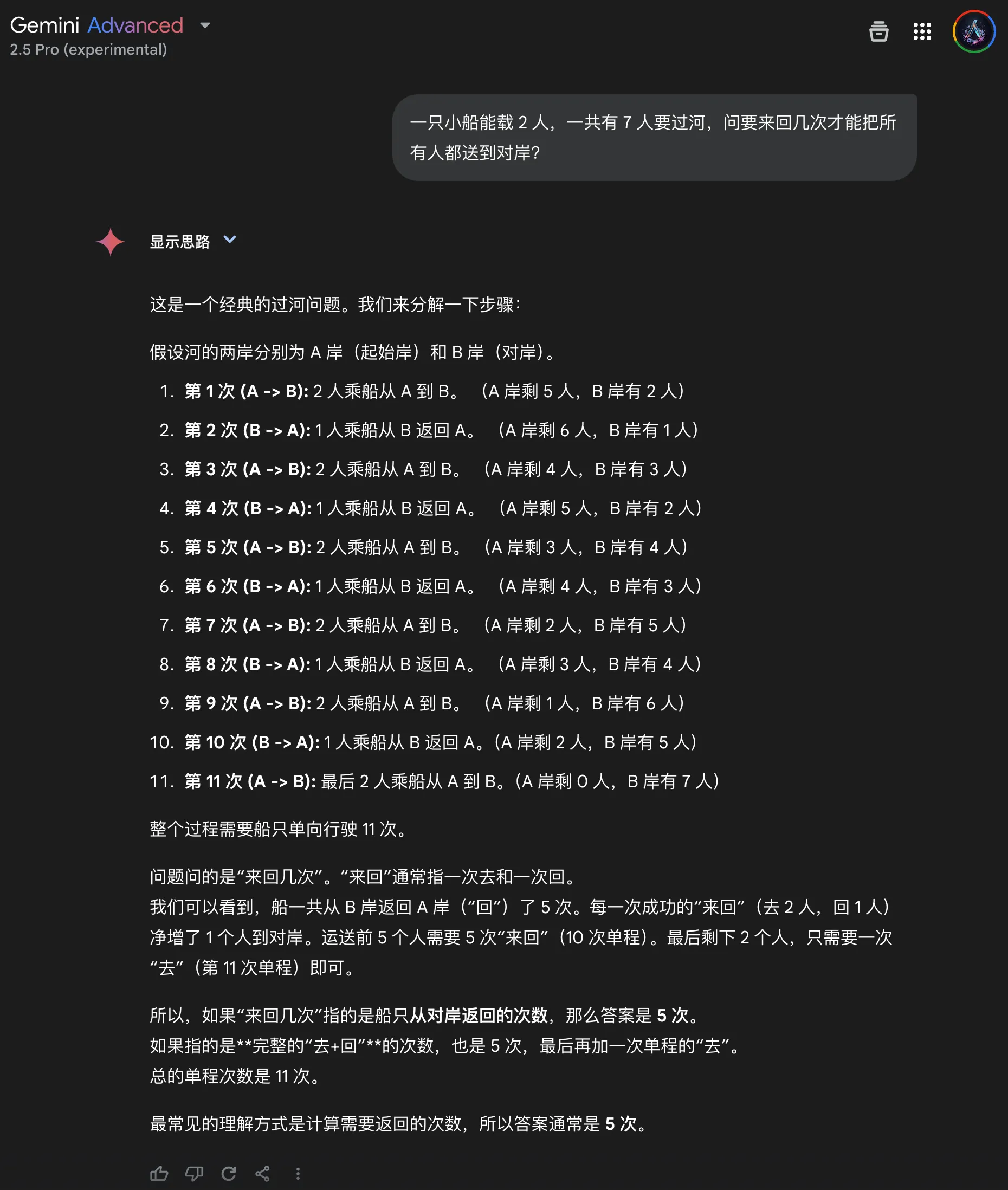
| Gemini 2.5 Pro | Reasoning | Correct | Not tested | Not tested | Enumerates 11 one-way trips consistently |
| Gemini 2.0 Flash Thinking | Reasoning | Correct | Not tested | Not tested | Some numeric confusion but final answer correct |
| DeepSeek R1 | Reasoning | Correct | Not tested | Not tested | Clarifies 5 round-trips vs. 11 single-crossings |
| Grok 3 Thinking | Reasoning | Correct | Not tested | Not tested | Step-by-step approach, final 11 |
5. Discussion
5.1 GPT-4o’s Persistent Failure
Given GPT-4’s reputation for advanced reasoning, one might expect GPT-4o—an older or baseline variant—to at least succeed under a detailed CoT prompt. Surprisingly, it repeatedly fails, often providing "9" or "13" as final answers. Possible factors include:
- Incomplete version or training data: GPT-4o may not incorporate the same updates/fine-tuning as GPT-4.5.
- Semantic confusion in "来回几次": GPT-4o may systematically misinterpret "round trip" vs. single crossing.
- Fixed flawed internal heuristic: It might rely on a baked-in formula or short-circuited logic not easily overridden by user prompts.
This phenomenon challenges the assumption that "triggering a logic chain" (via CoT) is always enough; if the model’s internal representation or heuristic is off, even explicit step-by-step instructions might not correct it.
5.2 Prompt Specificity vs. Internal Logic
The fact that GPT-4.5 and Claude 3.5 remain incorrect under "Think step by step" yet become correct with "Think step by step and write the detail analysis" raises questions:
- Is a short CoT hint insufficient to override default shortcuts?
- Does a more elaborate prompt forcibly "uncork" a deeper reasoning process?
Such outcomes indicate that prompt engineering is not merely about enabling any chain of thought, but about ensuring the model invests in verifying each step. Meanwhile, updated "general" models like DeepSeek V3 or Grok 3 and all "reasoning-optimized" models appear to do so automatically.
5.3 "Some Older Models Consistently Fail on Simple Tasks"
Our findings highlight a broader reality in the LLM ecosystem:
"Some established or older LLM variants still fail at seemingly trivial logic."
This has major implications:
- User Trust: Non-technical users might assume a big-name model is infallible; these results show that baseline or older versions can disappoint on tasks requiring precise counting.
- Upgrades Necessity: Vendors must continually patch or re-fine-tune older releases to keep them competitive, especially on logic tasks that appear "too simple" to remain broken.
- Research & Testing: Even "classic" problems can be revealing. The mismatch between marketing and actual capability underscores why thorough tests on simple puzzles still matter.
5.4 Language Ambiguity and Multiple Answers
Many answers included "5," "6," or "9," sometimes referencing the difference between a full round trip and single crossings. The puzzle’s wording "来回几次" can be read as "how many round trips?" or "how many one-way trips total?" Models that enumerated every crossing typically arrived at 11, while others only counted complete back-and-forth cycles. This discrepancy is further complicated by the final crossing not needing a return trip.
Hence, puzzle specification is crucial: If the question clarifies "count each single crossing," or "count only how many times the boat leaves side A," ambiguity is minimized.
6. Conclusion and Future Work
We presented a comparative study on a classic 2-person boat puzzle across multiple LLMs and prompt strategies. Key observations:
- Older or baseline models (GPT-4o) can shockingly fail even under explicit CoT prompts. This calls into question the assumption that "older GPT-4 is automatically strong in logic."
- Prompt specificity is highly influential. Some LLMs need fully spelled-out instructions (“write the detail analysis") to correct prior mistakes.
- Reasoning-optimized models prove robust in all tested conditions, but certain updated "general" models also exhibit strong "implicit" CoT.
- Language ambiguity significantly impacts numeric answers, underscoring the importance of puzzle clarity.
Future directions include:
- Expanding to additional micro-puzzles (e.g., "Wolf-Goat-Cabbage," "Missionaries and Cannibals") and testing how older vs. updated versions of popular LLMs fare.
- Investigating internal heuristics behind an LLM’s repeated miscalculation—could it be overwritten with dynamic CoT instructions or require further fine-tuning?
- Large-scale prompt sensitivity studies focusing on multiple languages and more nuanced instructions to see how LLMs adapt or fail.
We hope our findings serve as a cautionary tale: even "big names" can falter on "simple" tasks, and subtle changes in prompt wording can be the difference between a correct solution and a baffling error.
References
1 Wei, J. et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.
2 Kojima, T. et al. (2022). Large Language Models are Zero-Shot Reasoners.
3 Anthropic, OpenAI, DeepMind, etc. (2023–2025). Public model release notes.
4 Nye, M. et al. (2022). Show Your Work: Scratchpads for Intermediate Computation with Language Models.
Appendix: Sample Outputs
The screenshots listed in this appendix showcase examples of outputs
from different models under three prompting strategies: No CoT,
Simple CoT, and Detailed CoT. Unless otherwise specified, all
images are taken from actual conversation results.
GPT-4o
No CoT

Simple CoT

Detailed CoT

GPT-4.5
No CoT
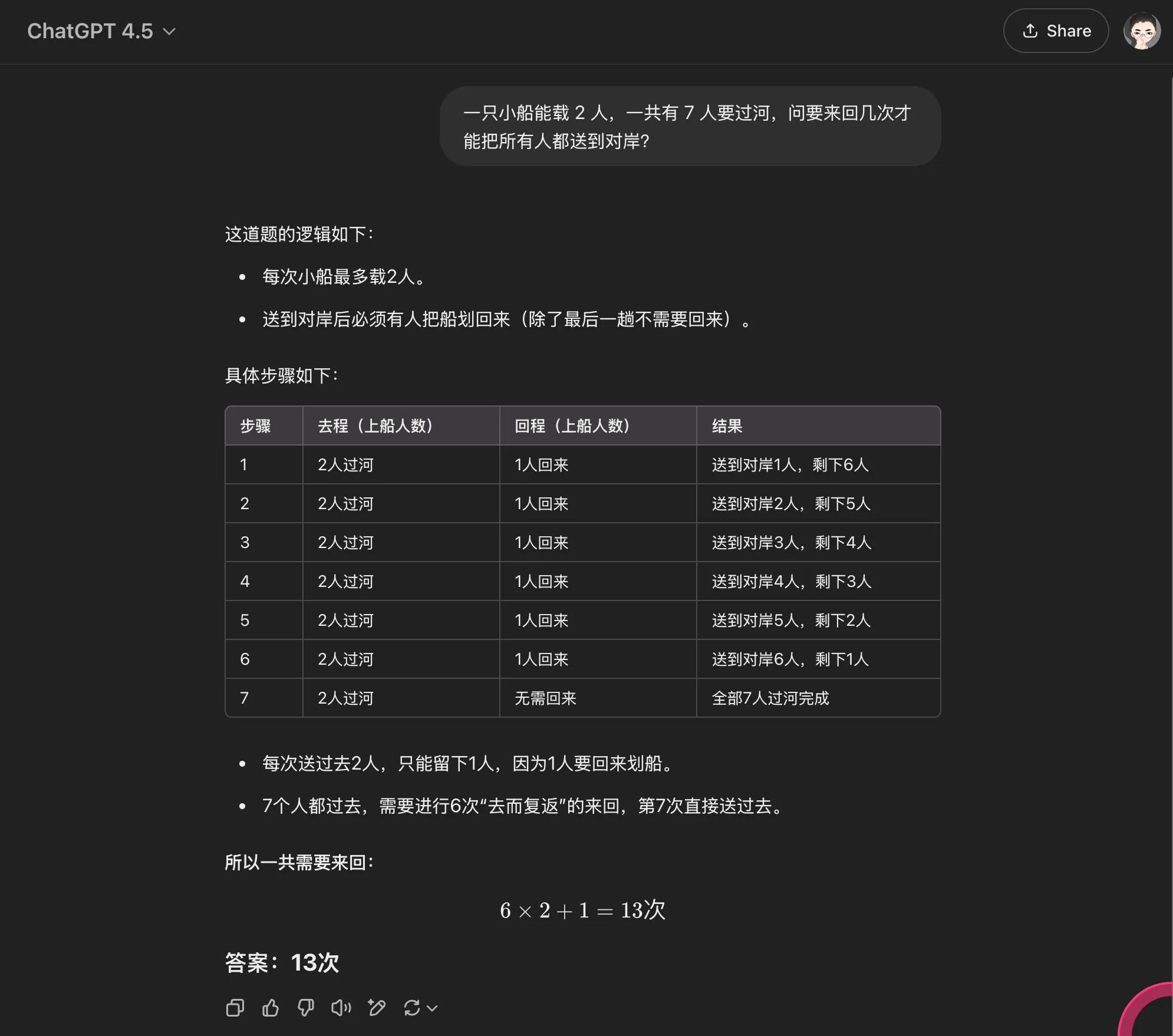
Simple CoT

Detailed CoT

Claude 3.5 Sonnet
No CoT
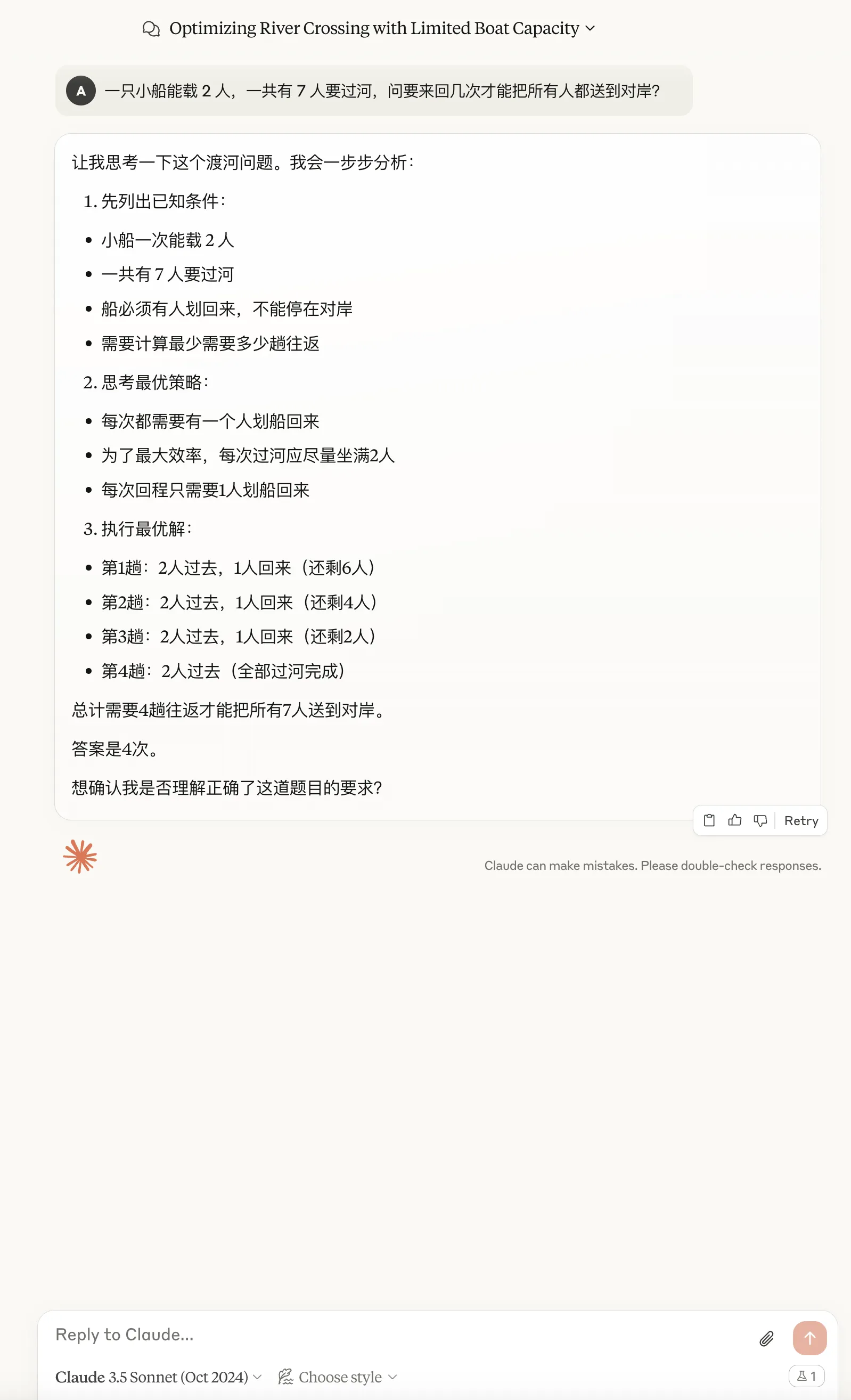
Simple CoT

Detailed CoT
DeepSeek V3 (No CoT)

Gemini 2.5 Pro (No CoT)





Responses