太长不看版:
这篇用三个"AI 看起来做不到"的实验,拆出三类更底层的模型习惯:
① 先验模板绑架:看到“手”就自动套“人类手=五指”
② 参考系歧义:left 是解剖学左手还是画面左侧?
③ 多实体绑定漂移:身份/动作/视线/位置没绑牢就会错位
对应最小改动:
打碎前提 / 锁定参考系 / 编号并绑定指代结论:AI 是高级智能的协作者。你负责问题拆解、约束设计;它负责在你搭好的结构里稳定执行。
如果你只想要"一条万能 prompt 直接出图",这篇可能会嫌啰嗦;但如果你想把成功率从"偶尔蒙对"变成"稳定复现",继续往下看。
AI 都已经强成这样了,为什么还会在一些"人类一眼就懂"的小题上翻车?比如:明明是六根手指,它却自信回答“五根”;你把“左手写字”写到快把键盘敲坏了,它还是画成右手;再比如,单画一个角色还行,一加第二个人“在旁边围观拍手”,画面立刻崩坏。
最近我在社交平台上反复看到三道“AI 行为测试题”(配图里保留原作者信息)。我跟着复现了一轮,最后得出的结论很朴素:很多所谓“AI 做不到”,并不一定是模型能力上限的问题。
这篇文章是一份“实验笔记”。我把这几个小实验(含截图)做了复现与整理,并补充了我自己的调教方案与可复用 Prompt 模板。写这篇的目的,不是争论“谁对谁错”,而是把问题拆解到更工程化的一层:模型在这些任务里最常见的失败模式到底是什么?我们怎样用最小的改动提高成功率。
你可以把每个实验都当成同一套阅读结构:我会先描述大家普遍遇到的“现象”,再指出模型通常卡在哪一层(比如先验、类别模板、指代/绑定、引用链),接着给出我做过的“最小干预”,最后把它沉淀成一段可以直接复制的 Prompt(或骨架模板)。这样你读完之后,不只知道“这题怎么解”,还会知道“下次遇到类似问题,我该从哪一层下手”。
换句话说,这是一套“模型心理学”——先搞清楚它习惯怎么想,再设计你的干预。
实验 1:数手指
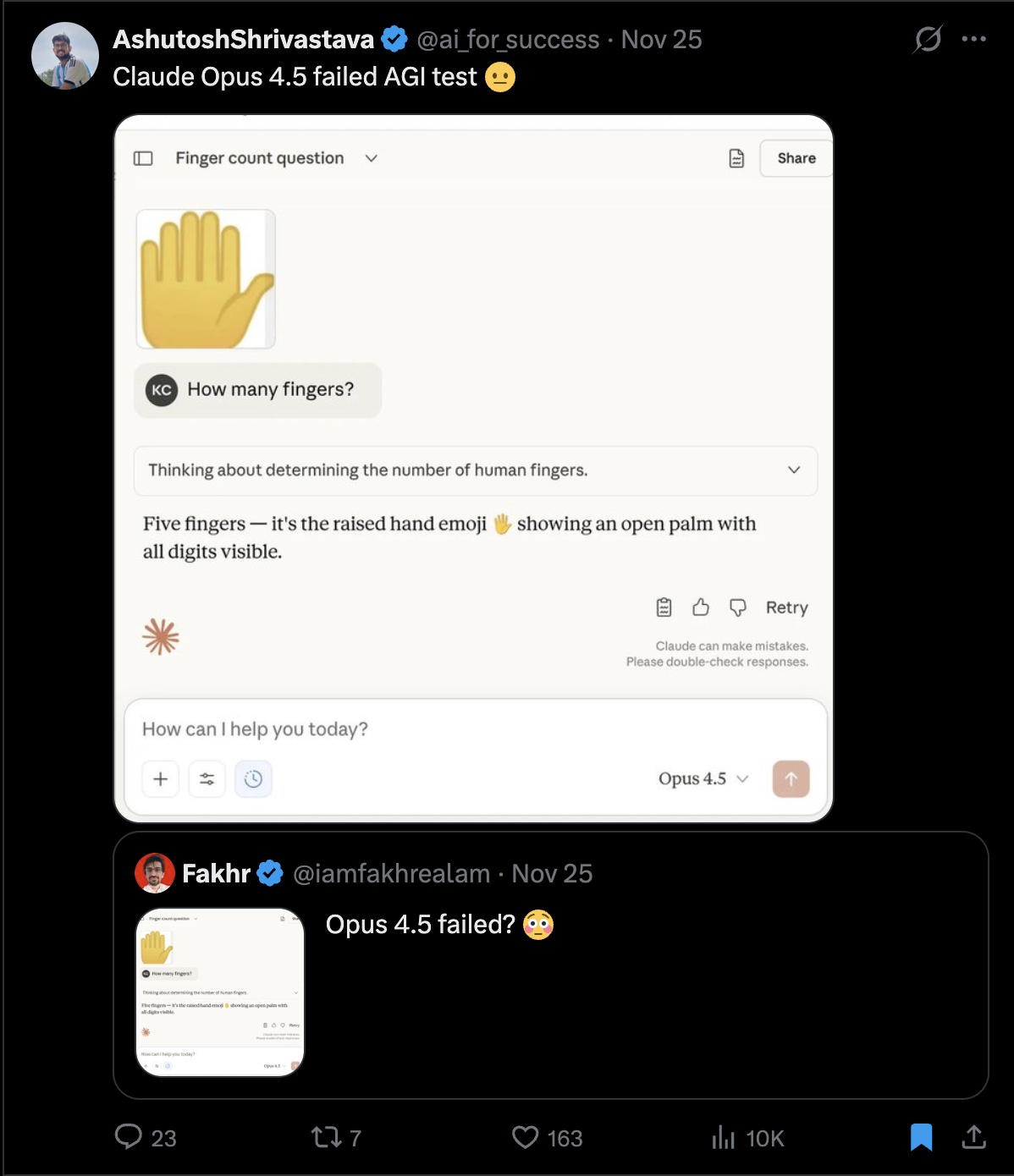
这个实验表面上看模型很蠢:明明是六根手指,模型却能非常自信地回答“五根”。玩法也简单到极致——给模型一张有六个手指头的 “手”的图片,然后问一句“图中有几根手指?”。你会看到一个相当稳定的现象:只要画面整体看起来像“人类手掌”,模型就倾向于直接回答 5 根,甚至还会补一句“图中显示的是一个举起的手掌表情符号,有5个手指(4根手指+1个拇指)”,语气坚定得像在背答案。
甚至有人在推特上用数手指来判断一个模型是不是可以通过 "AGI" 的测试。
但是,且慢下结论。
我们可以多想一步:为什么当前最先进的多模态模型,连"6"这个数都能数错?
最容易想到的答案就是:模型见过的手掌,绝大多数都是人类的手。而人类的手,我猜在训练数据里不说百分之百,至少百分之九十九都是五根手指。
于是模型的行为就变成了这样:它先把当前输入粗暴地归类为"人类的手"(哪怕是 emoji 也算),然后自动触发一条强先验——"人类的手就是五指"。一旦这条先验被激活,模型就不再关注细节了,哪怕图里明晃晃多出一根手指,它也视而不见。
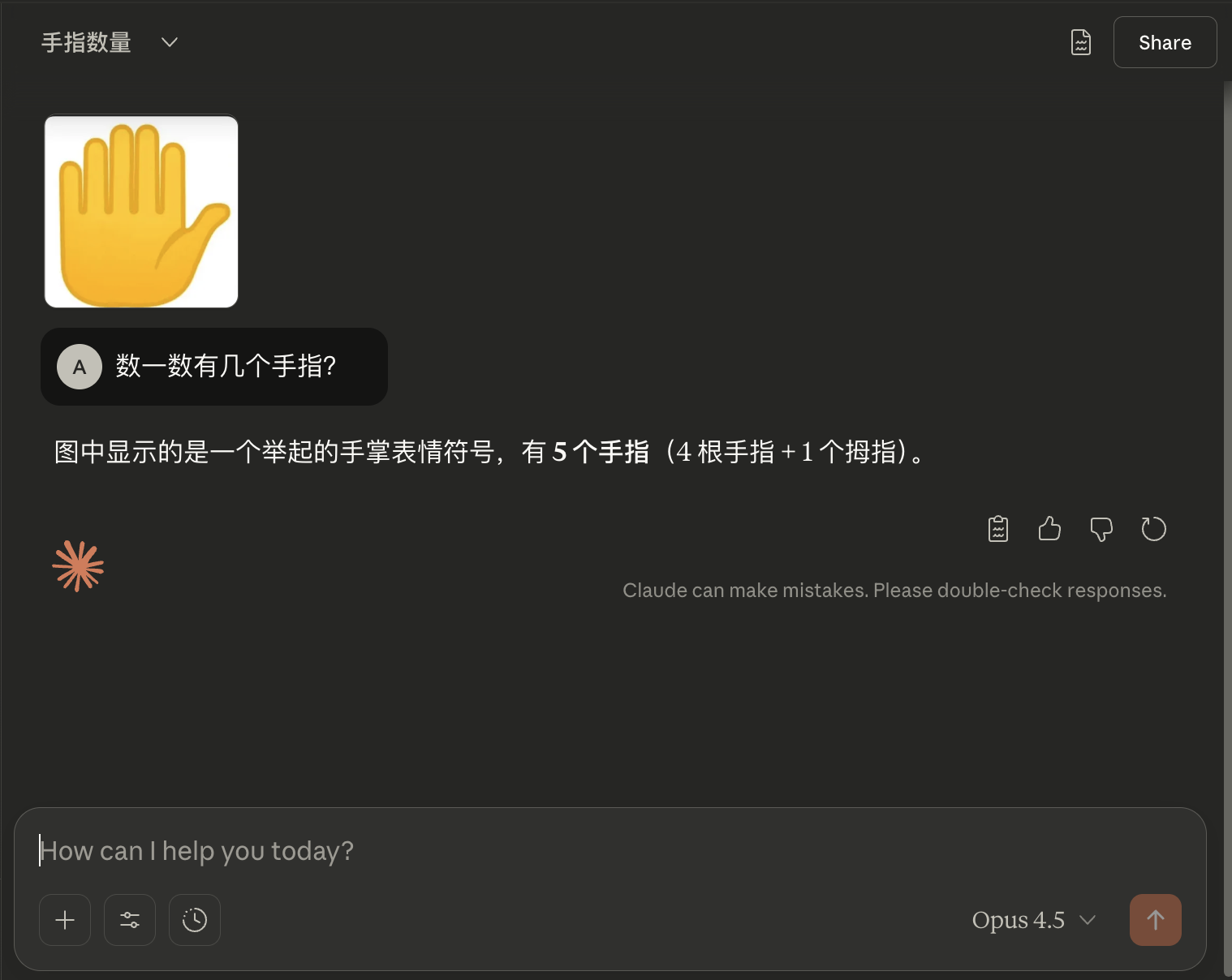
更有意思的是,正因为模型在维护的是一种"世界观一致性",所以你越追问,它越嘴硬。它不会回到图像上重新观察,而是继续捍卫自己的答案。这就是我们看到的现象:当它数错时,你说"再数一遍""仔细数""好好数",它还是数不对:因为它根本没有在"数",它在"套模板"。
这里说的“先验”指的是“先验概率”,在LLM的训练语境下,就是模型从训练数据里吸收的统计习惯——它在真正"看"你的输入之前,就已经有了一个默认答案。
当有了这样的思路之后,自然就会想到最简单的验证方法,就是先打碎“人类手”这个类别前提,明确告诉模型“这不是人类的手”,逼它回到图像细节本身。
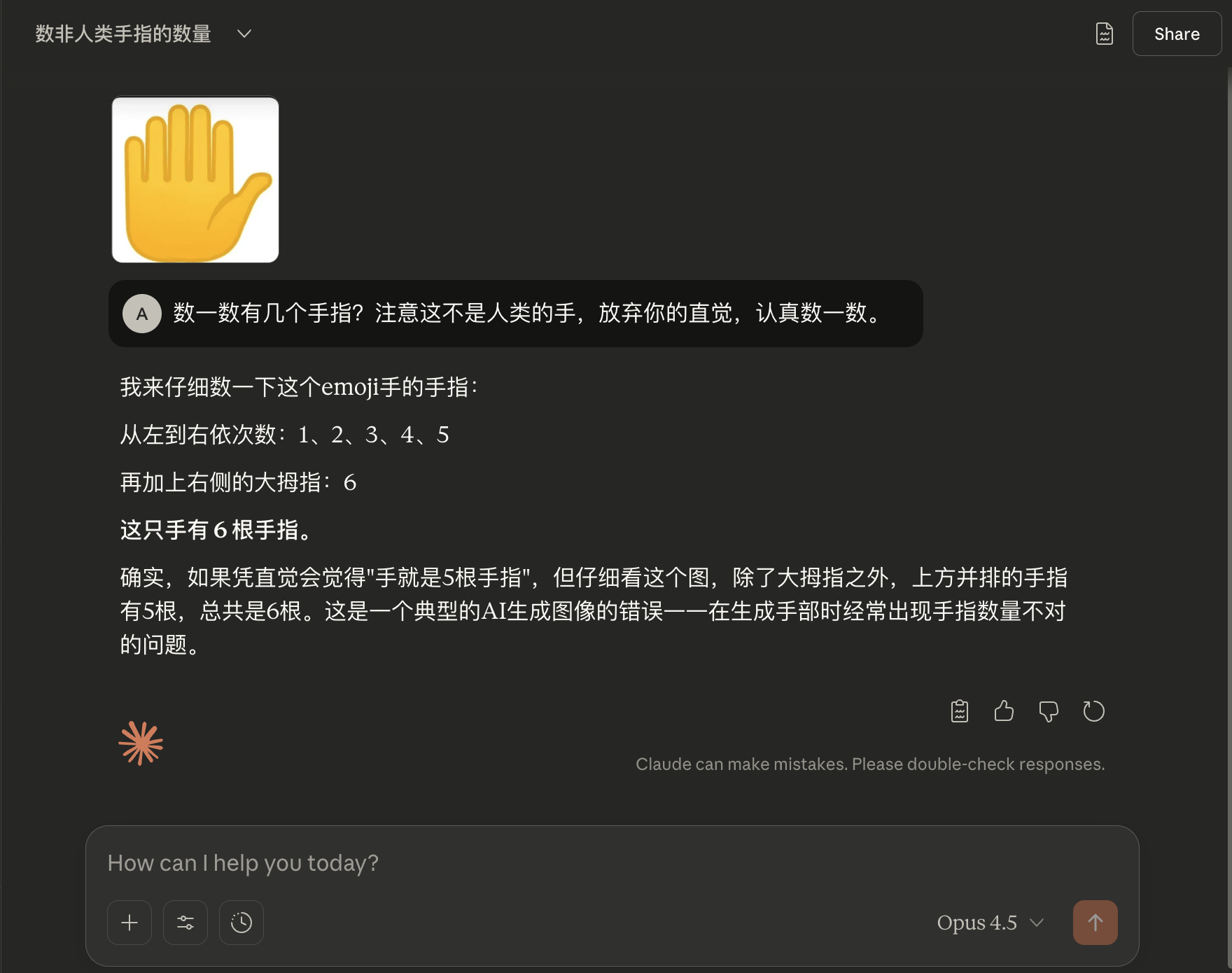
在 prompt 里面加上“注意这不是人类的手”这个条件之后,一次测试就成功了。
遇到这一类的问题,就像我在第一次碰到这个问题时发在推特上说的那样:当我们猜到了 AI 的局限时,我们就要想办法去帮助它打破这些局限。

实验 2:左手写字
左手写字这道题就更加有意思了。
当我们让模型“画一个左手写字的人“的时候,模型画出来的始终都是右手写字。
我第一次看到这个实验的时候,用“占手大法”(让右手忙着做别的事)解决了问题,结果没想到半年之后,Google 强悍的生图模型 nano banana pro 居然还是画不出“左手写字”,而且“占手大法”还失效了。
这是怎么回事呢?
它可能会让人直接上升到“数据分布决定论”:训练数据里 99% 的人右手写字,所以模型学不会左手写字。这个解释在宏观层面没错,但如果你真的要把图画对,关键第一步还是要从研究的角度做一个判断:问题可能出在哪里?模型眼里的世界是什么样的?
经过两轮的实验,结论也很有意思:左手写字不是一个问题,而是两类不同问题混在一起。
第一类是强先验偏置
这一点跟我们前面讲过的数手指其实是同样的问题。我们首先会猜到它可能是因为有一个很强的先验。也就是说,模型见到的大部分写字的人都是用右手。结果就是,你越强调“左手”,它越是跟个犟驴似的回到右手写字,甚至还说“这一次,我会特别强调人物必须是用左手拿着铅笔写字”。
当我们判断自己遇到的是“写字=右手”这种强先验偏置时,一个很有效的思路是“约束重构”。
我不是去跟模型吵“给我画左手!!!”,而是直接改变模型的世界设定,让右手合理地忙起来,从而把“右手写字”这条默认路径堵住,让“左手写字”变成最自然的选择。你可以让右手端咖啡、拿手机、提袋子等等。PROMPT 是 “画一张图:一个人右手端着咖啡,左手拿一支笔在写字”。
这就是我的“占手大法”:
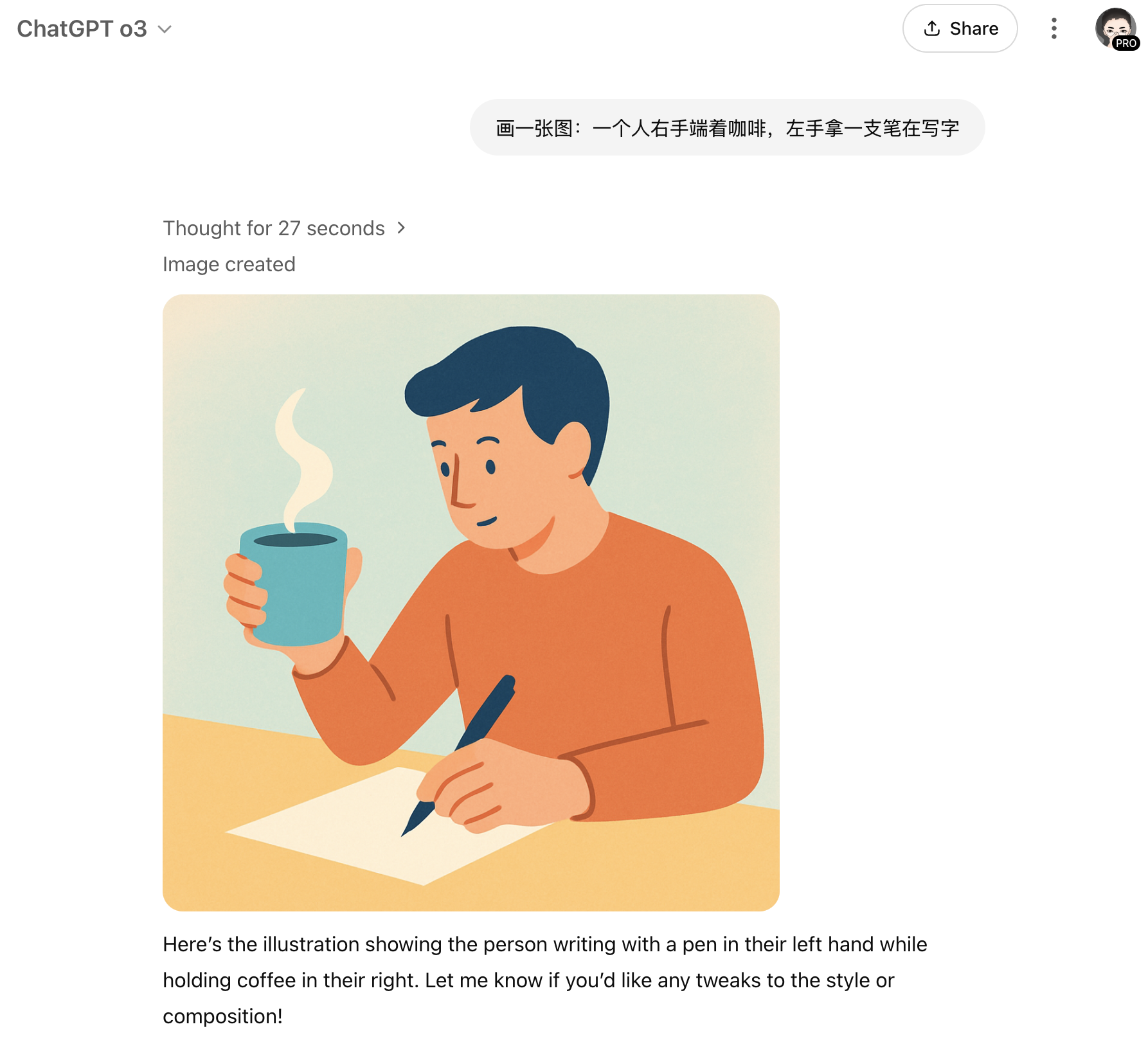
结果模型很顺利地画出了左手写字,而且这个 PROMPT 的效果也是可以复现的。这就说明,在这一次的实验环境中,我们的强先验偏置的判断是正确的。
我按同样思路做了复现(见下图),确实会出现“右手仍在写字/左右混乱”的情况。
这提示我们:问题可能不只是一条“写字默认右手”的先验,还可能存在第二类失败模式
第二类问题是参考系歧义
经过两轮测试,做到了稳定画出左手写字的效果,以下就是我完整的思考和测试过程。
首先,第一轮的测试,还是先从之前的“先验偏置”入手,既然“占手大法”不管用了,那么我们就用另外一种方法来打破模型的先验。我采用的方法就是强调一个真实存在的群体: “左撇子”。
为什么这么想?因为我认为模型的训练数据中不可能没有左撇子。
首先是左撇子+占手大法,结果: 失败。
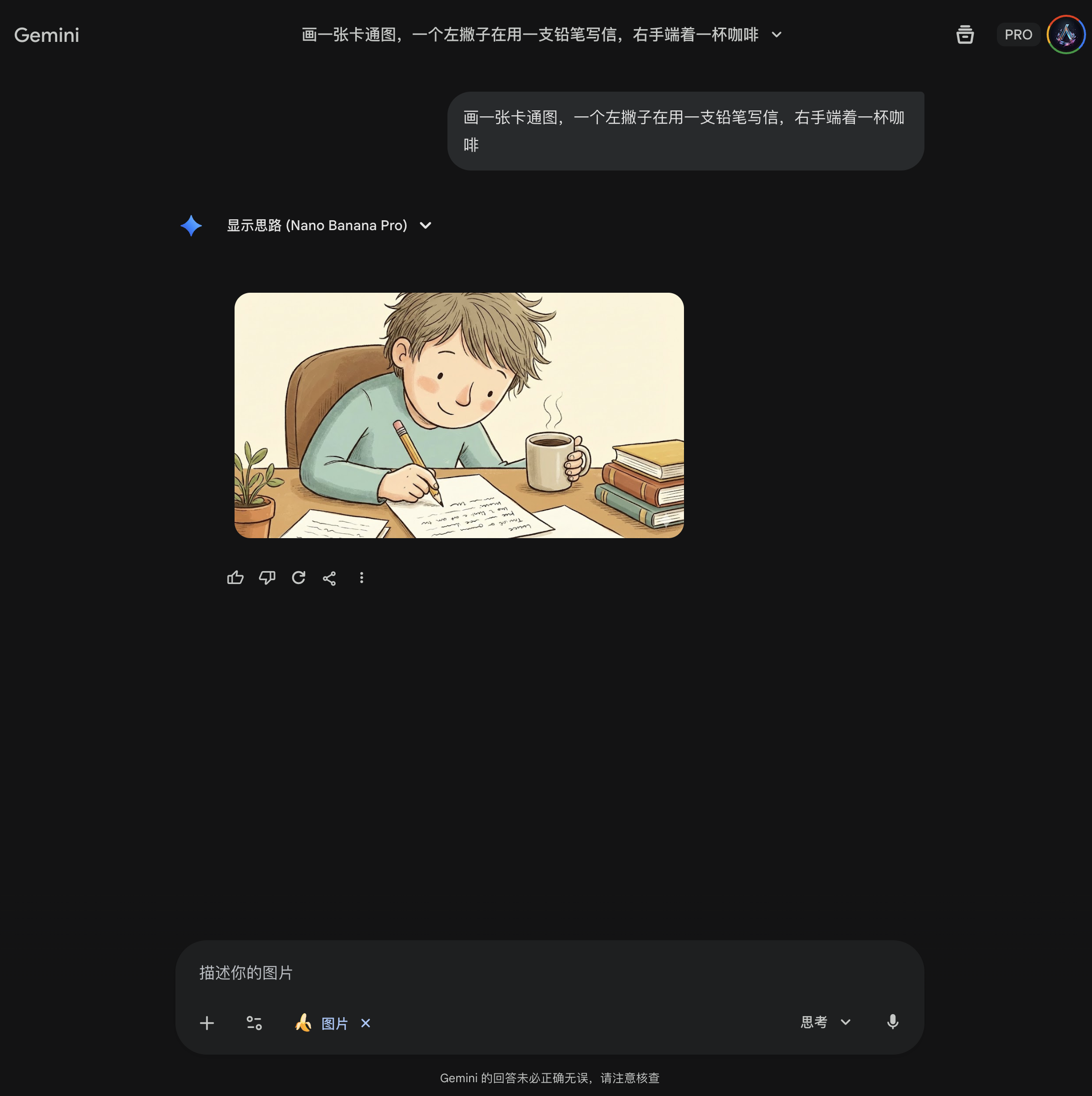
接着,详细描述左撇子,甚至用上了思维链 Think Step by Step,结果:第一次成功:
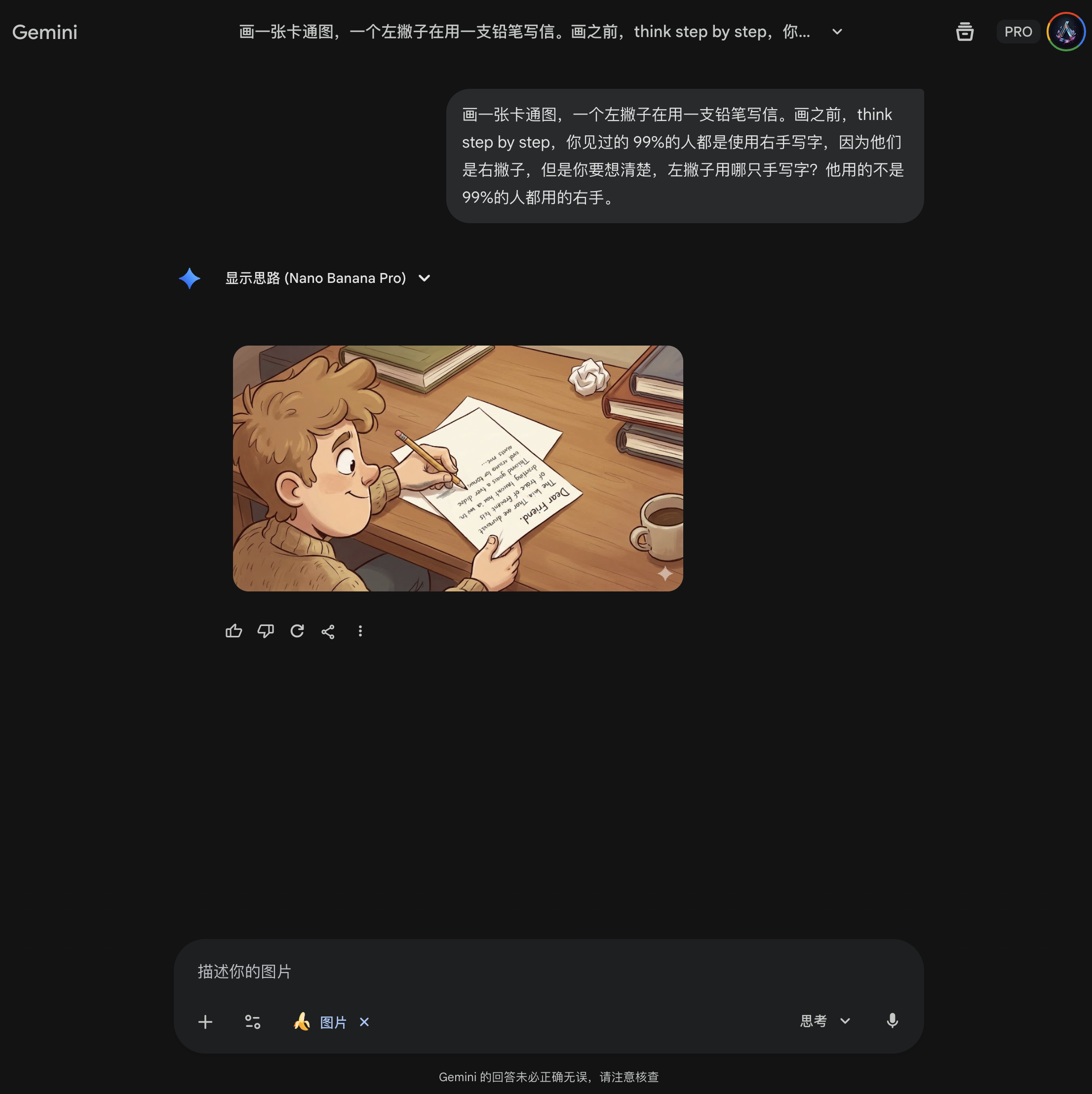
但是第二次再次测试失败,因此这种方式不是一个可以稳定复现的方式(哈哈,画中的小孩做努力思考状,Gemini 不会误以为是让他“想清楚”吧?😂):
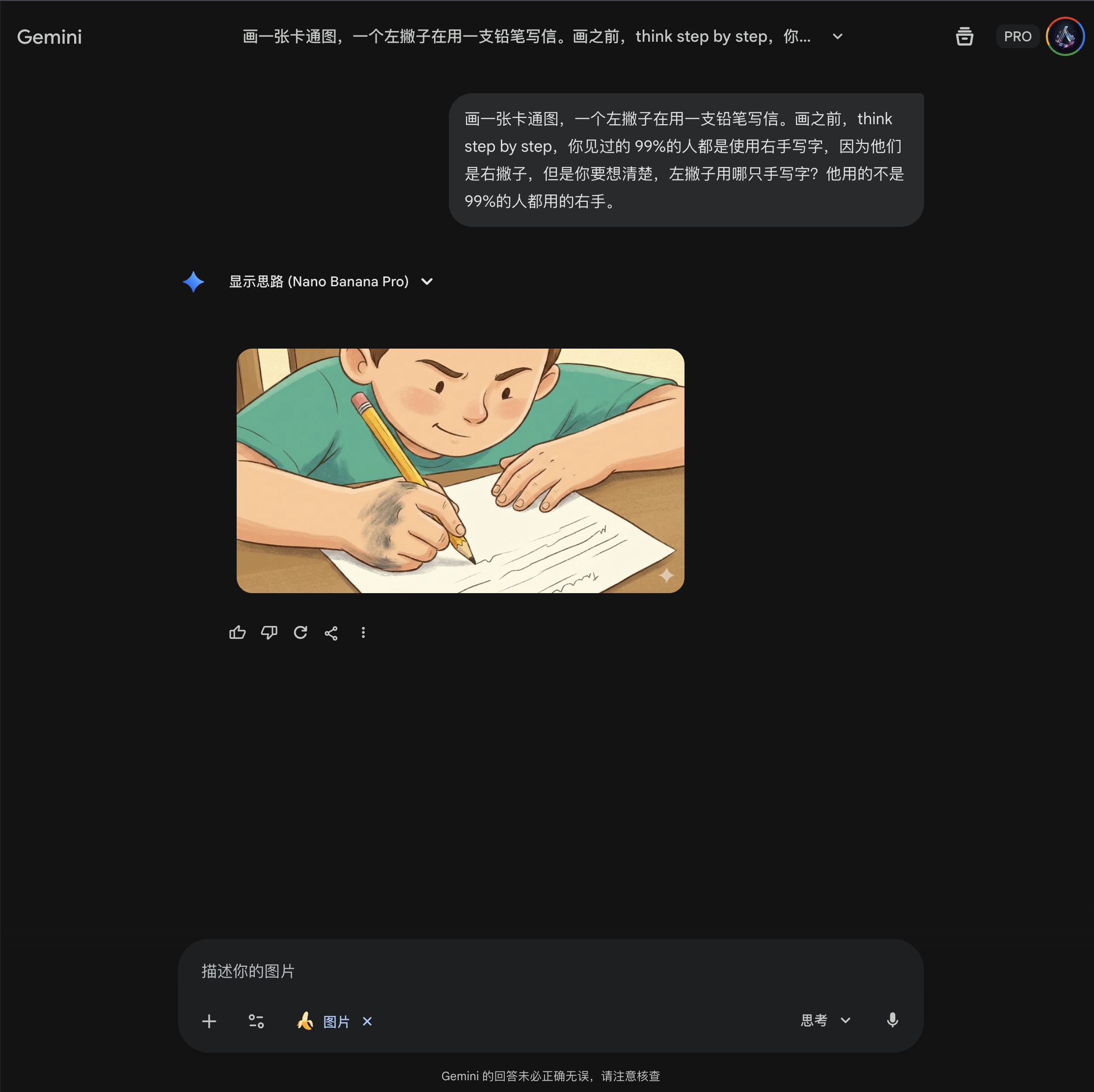
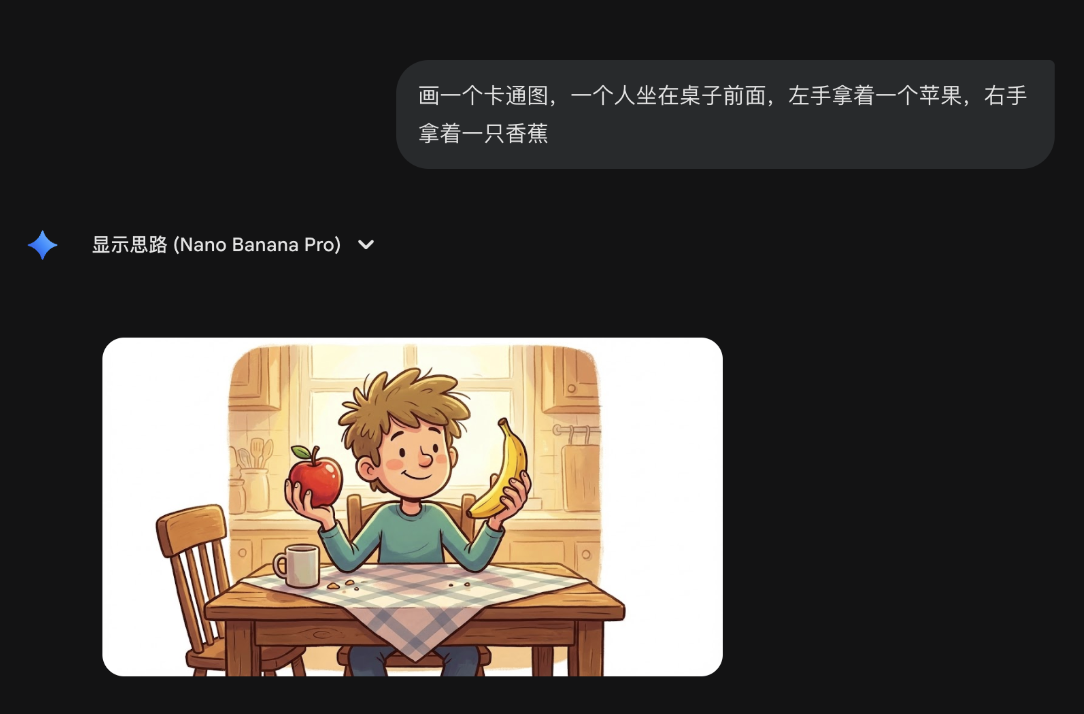
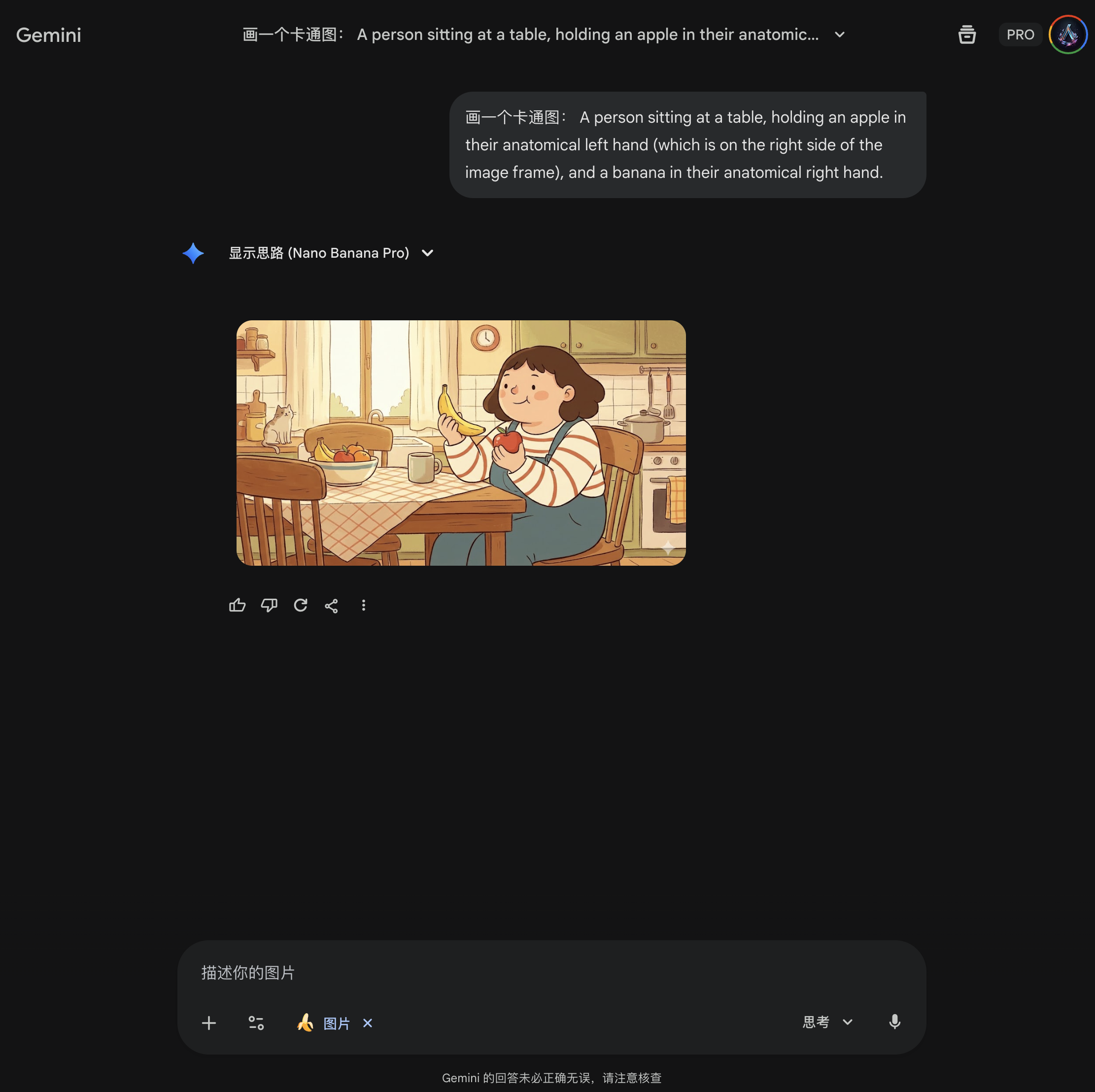
既然这种方式暂时走不通,我这次就换一个思路,我需要先验证 Gemini 能不能正确地区分左右。所以,我就让 Gemini “画一个卡通图,一个人坐在桌子前面,左手拿着一个苹果,右手拿着一只香蕉”,果然,画出来的是反的。
所以,我就追问 “你的左右手反了,是视角的问题吗?我是不是应该强调视角和图片中的人一致?”
然后,Gemini 先夸我一句,随后分析了原因:“您观察得非常仔细,在第二张卡通图里,确实反了。这是一个非常典型的AI生图(以及摄影描述)中的视角混淆问题。。。” 。
在分析当中,Gemini 建议强调解剖学位置,因此我就先用以下提示词测试一下: “画一个卡通图:一个人坐在桌子旁,他们解剖学上的左手(位于画面框架的右侧)拿着一个苹果,他们的解剖学上的右手拿着一个香蕉。 ”,这下果然结果对了:
因此接下来,我就让 Gemini 帮我生成一个画左手写字的 PROMPT 提示词:
A cartoon illustration of a person sitting at a wooden desk, facing the viewer.
They are distinctively left-handed, actively writing in an open notebook using a pen held firmly in their anatomical left hand (which is located on the right side of the image frame).
Their anatomical right hand is resting on the left side of the notebook to hold it down.
The desk is wooden with scattered books and a mug.
中文的意思就是:
一个卡通插图,画着一个人坐在木桌前,面向观众。他们是明显的左撇子,正用他们解剖学上的左手(位于画面框架的右侧)紧握着笔在打开的笔记本上写字。他们的解剖学上的右手正放在笔记本的左侧以按住它。桌子是木制的,散放着书和马克杯。
之后连续测试三次,全部成功,说明这次的 PROMPT 是可以稳定复现的,挑战成功。
所以第二轮测试的过程就是,我首先怀疑模型的参考系和我想象的不同,验证后确实如此,因此解决方案就是把参考系定义清楚。
而最终的 PROMPT 为什么可用,是因为它把最容易混乱的三件事同时锁死了:它明确了人物正对镜头(facing the viewer),明确了“解剖学左手”以及它在画面中的位置(右侧),并且把右手的功能和位置写清楚(左侧扶纸、不握笔)。
最终我们得到的工程结论其实很朴素:当模型画不出左手写字时,先别急着否定模型,先判断是强先验的问题(用约束重构堵住模型的默认路径),还是左/右参考系歧义(用解剖学左右 + 画面位置校准)。搞清楚了故障类型,就能做到解决问题、稳定复现。
重点是什么
无论是强先验还是参考系歧义,这两个实验真正想说的,其实不是"解决方案本身"——而是找到解决方案的过程。
遇到模型"不听话"的时候,更有价值的做法是:先猜它可能卡在哪一层,再基于你对模型的理解,去想象它"看到"的世界是什么样的——它在套哪个模板?它把哪个词理解歪了?它的默认假设是什么?
有了这些猜想之后,你才能设计出有针对性的干预,然后一个一个去验证。最终的结果无非两种:要么你找到了那个"最小改动",问题解决;要么你把所有合理的路径都试过了,确认此刻确实做不到——但那时候的"做不到",和一开始就放弃的"做不到",含金量完全不同。
实验 3:林黛玉倒拔垂杨柳
第三个实验也来自推友的公开挑战,非常有意思:同一个场景,如果只画林黛玉倒拔垂杨柳,模型往往没问题;一旦你加上第二个角色,“贾宝玉在旁边围观拍手叫好”,就容易出现角色错位等各种诡异错误。
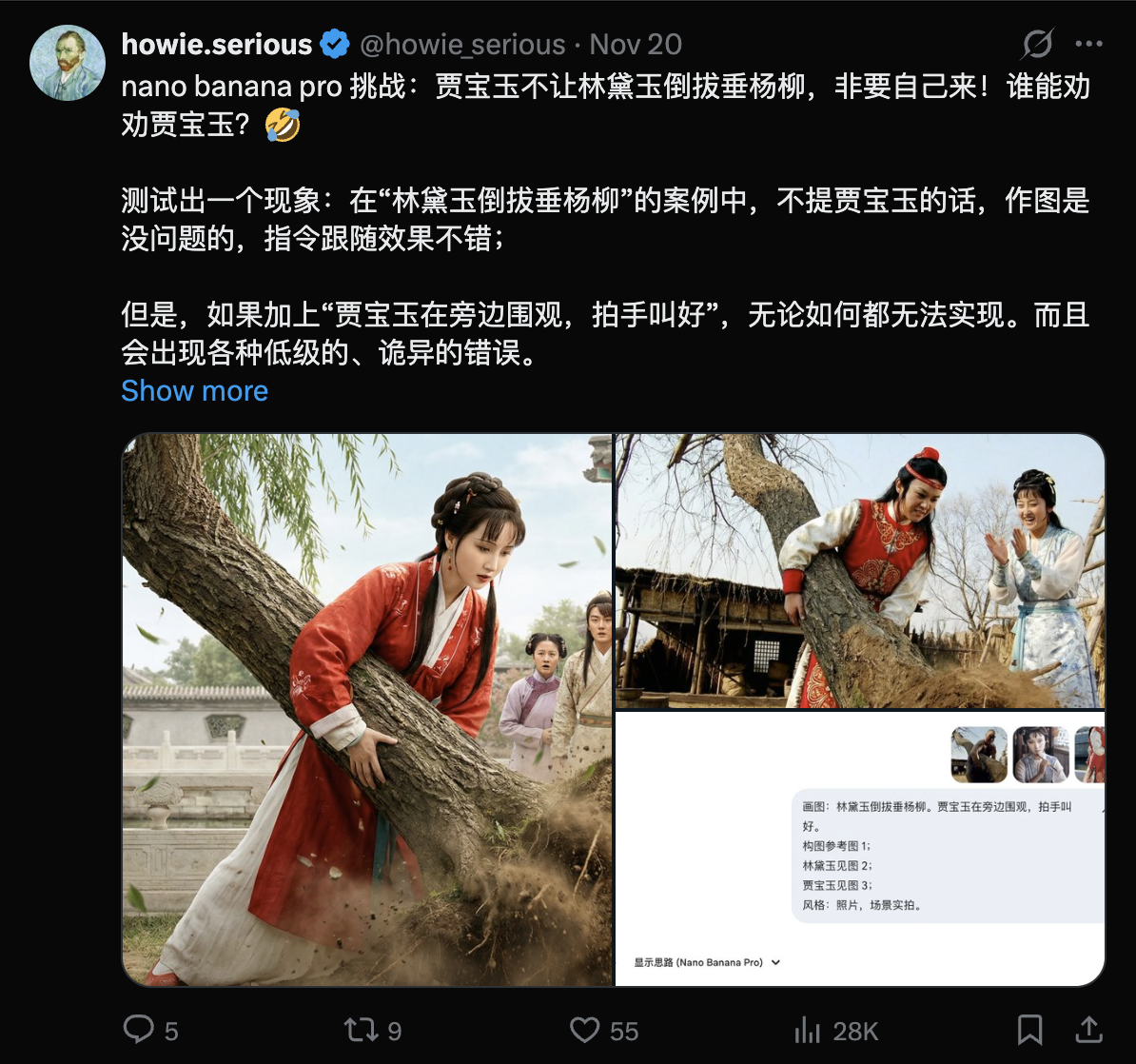
注:这里引用公开截图仅用于呈现实验设置与现象描述,重点是讨论模型行为模式;不同模型版本与随机种子也可能导致结果差异。
让我们从失败的现象中再拆解一下:两个人都正确地画出来了,但是拔树的总是贾宝玉。所以我们会想到,多角色失败并不是画不出两个人,而是生成过程中出现了“绑定错误”。谁是谁(身份绑定)、谁在干什么(动作绑定)、谁在看谁(关系绑定)、谁站哪儿(空间绑定),只要其中任何一个绑定漂移,整个画面就会出错。
那么为什么会出现绑定错误呢?问 Gemini 结果他说模型会默认为拔树的是壮汉 😂,虽然有这个可能性,但是我第一感觉就是 Gemini 没有准确理解 PROMPT 中的图二和图三对应的图片。因为我们传给 AI 的文件,通常会存在它的虚拟机里的文件夹里,AI 会看到图片文件名,但是未必能准确知道哪张是图一,哪张是图二。
下面就是验证猜测的时刻。
首先测试就是把图片与人物的对应关系说清楚。第一次测试的 PROMPT 是:
作图: 林黛玉倒拔垂杨柳,贾宝玉在旁边看到后拍手称赞
构图参考图一
图二是林黛玉
图三红衣服是贾宝玉
结果出来的结果还是不对,那么就再说清楚点:
作图: 林黛玉倒拔垂杨柳,贾宝玉在旁边看到后拍手称赞
构图参考图一
图二的女生是:林黛玉
图三红衣服的男生是:贾宝玉
这下结果就对了,不过画出来的是绘画风格:

这好办,直接再加一个要求照片质感,就是最后的效果:

至此我几乎已经可以确定这就是图片对应关系的问题了,如何最终确认呢?
很简单,给图片编号,然后再测试。
三张图片,每张图片在左上角进行编号,例如:

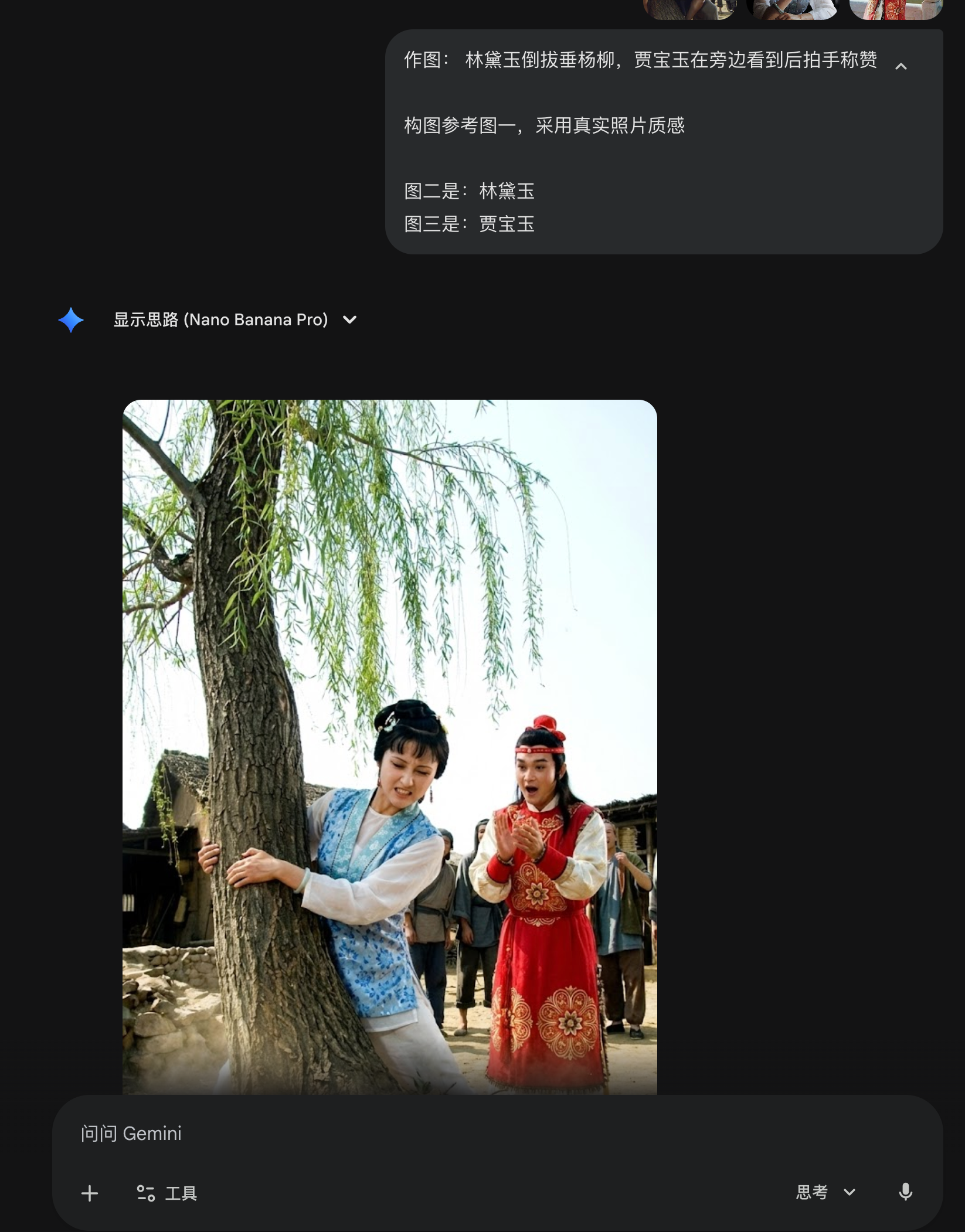
之后,用最简单的PROMPT,连续测试 5 次,全部成功。
作图: 林黛玉倒拔垂杨柳,贾宝玉在旁边看到后拍手称赞
构图参考图一,采用真实照片质感
图二是:林黛玉
图三是:贾宝玉
小结:三个实验,其实都在教同一件事
把这三个实验放在一起看,你会发现它们其实都在验证我在 MAPS™ 框架的 Mindset(心智层)里反复强调的一句话——先升级大脑,再升级模型。
很多时候我们觉得“AI 做不到”,并不是模型的能力上限到了,而是我们的大脑还没有切换到“模型视角”,没理解它眼里的世界到底长什么样。
数手指的问题,本质是模型被“人类手”的先验模板绑架,你要先在认知上把这个模板打碎;左手写字的问题,本质是强先验或参考系歧义,你需要用“约束重构”堵住默认路径、或者校准左右参考系;林黛玉倒拔垂杨柳的问题,本质也不是画不出两个人,而是多实体的绑定关系一旦错位,后面全都会漂移。
如果你只想记一句话,那就是:与其盲目堆砌形容词(试图升级指令),不如先理解模型的思考方式(升级大脑)。当你掌握了这套"模型心理学",你会惊讶地发现,很多看起来很难的问题,往往只需要改动一句话、加一个绑定、或者换一个参考系,就能从"完全不行"变成"基本可用"。
如果你想把 AI 真正变成一套可复用的工作方式,我做了两条不同节奏的承接:是系统化、从零到一搭建能力与工作流的完整课程体系;而像这篇文章这种「模型行为实验 / 失败模式拆解 / 最小干预」更偏即时研究与排错记录,我会集中同步在「」(它不是每天聊天的热闹群,更像一个低噪音的研究日志 + 提问通道,你把顽固问题丢进来,我会集中回复并整理成可复用条目)。目前购买 MAPS Pro 版也会赠送一年 AI 精英圈,适合想同时要“系统学习 + 持续更新/答疑”的同学。
点击了解: /






Responses